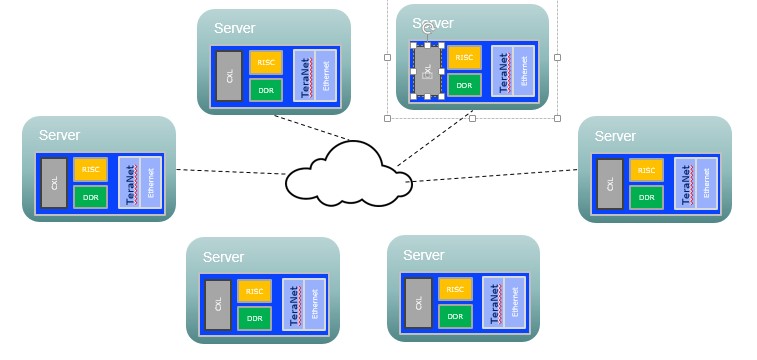
現今AI人工智慧的應用普及,AI伺服器的需求出現爆發式的增長,帶動了全球市場經濟的增長與突破,產業對AI伺服器的規格與效能也更加追求極緻。隨著CXL(Compute Express Link)3.0版本的萌芽,提高記憶體的頻寬和加大記憶體的容量,同時協助主CPU降低應用負載,獲得更高效能與更低的延時將是產業的主流方向。
宏芯在AI智能影像深耕多年,掌握了各個相關的關鍵技術,推出了一系列包括CXL, DPU, NPU等AI伺服器領域的協作處理晶片,在顛覆性的創新領域,提供完整的解決方案,提升廣泛的主CPU應用效能和效率,支援高效能AI伺服器應用不斷升高的各項要求,同時還能降低整體的擁有成本。
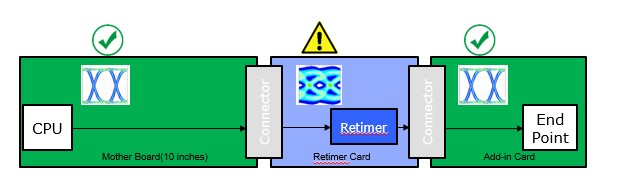
隨著印刷電路板上傳輸的電子訊號速度越來越快,訊號衰減的問題也變得更為嚴重。以PCIe Gen4為例,在一般的印刷電路上,訊號傳輸距離通常只能達到15英吋,若是採用PCIe Gen5,訊號傳輸距離更會縮短到10英吋以內。能有效延長PCIe訊號傳輸距離的重定時器(Retimer),為未來伺服器、高速網路交換設備主機板上常見的配套方案。
-Support 32 GT/s, 16 GT/s, 8 GT/s, 5 GT/s, and 2.5 GT/s Data Rates
-Support Low-Latency Mode
-Supports Hot Plug and Hot Un-Plug
-Supports SRIS, SRNS, and Common Clock Systems
-Lane/Port Debug Registers
-Support Tx/Rx Lane Reorder
Features
-Compatible with PCI Express® Gen-5/Gen-4/CXL3.0/CXL2.0/CXL1.1-Support 32 GT/s, 16 GT/s, 8 GT/s, 5 GT/s, and 2.5 GT/s Data Rates
-Support Low-Latency Mode
-Supports Hot Plug and Hot Un-Plug
-Supports SRIS, SRNS, and Common Clock Systems
-Lane/Port Debug Registers
-Support Tx/Rx Lane Reorder

AI 深度學習運算對記憶體的需求呈現無窮的需求, 例如單一中央處理器最多只能配置8個記憶體通道,獲得768GB記憶體容量,以及260至320GB/s記憶體頻寬。而安裝CXL擴充記憶體後,能大幅增加了50%CPU可用的記憶體容量與40%頻寬。
-PCIe 5.0/CXL Type-3 device supporting CXL 1.1 and 2.0 memory expansion
-PCIe 5.0/CXL interface, supporting up to 32 GB/s data rate (x8 lanes)
-Support Memory pooling and sharing for heterogeneous CPU/GPU topologies
-DDR Capacity up to 2TB
-Support up to DDR4 and DDR5
-Advance memory cache for enhance performance
-Support Memory RAS features
Features
-Integrated CXL controller, DDR controller and Micro-processor-PCIe 5.0/CXL Type-3 device supporting CXL 1.1 and 2.0 memory expansion
-PCIe 5.0/CXL interface, supporting up to 32 GB/s data rate (x8 lanes)
-Support Memory pooling and sharing for heterogeneous CPU/GPU topologies
-DDR Capacity up to 2TB
-Support up to DDR4 and DDR5
-Advance memory cache for enhance performance
-Support Memory RAS features
邊緣運算(Edge Computing)是一種網路運算架構,運算過程盡可能靠近資料來源以減少延遲和頻寬使用。目的是減少集中遠端位置(例如「雲」)中執行的運算量,從而最大限度地減少異地用戶端和伺服器之間必須發生的通信量。近年來,技術的快速發展使硬體趨向小型化、高密度以及軟體的虛擬化,讓邊緣運算的實用度更加可行。
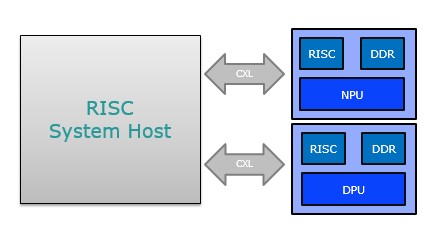
應用目標為Arm Neoverse 平台/RISC-V平台邊緣運算伺服器加速卡,藉由更專注的 DPU(Data Processing Unit), NPU(Neural Processing Unit )等輔助運算單元設計, 加速RISC的運算處理能力。
應用目標為Arm Neoverse 平台/RISC-V平台邊緣運算伺服器加速卡,藉由更專注的 DPU(Data Processing Unit), NPU(Neural Processing Unit )等輔助運算單元設計, 加速RISC的運算處理能力。
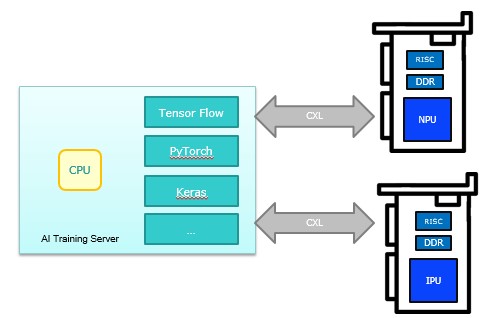
Machine Learning架構一直在演化推陳出新, 此專案目標為設計有別於GPU更高效率客製化AI Training解決方案例如GAN Deep Learning等等各種Net應用架構, 亦能為移動裝置提供低成的本高速運算AI NPU解決方案
除了應用於AI Server外, 我們更著重提供個人用戶更低的架設成本與更快速的更新迭代運算輔助單元。
除了應用於AI Server外, 我們更著重提供個人用戶更低的架設成本與更快速的更新迭代運算輔助單元。
透過獨有Hyper TeraNet平台, 藉由CXL高頻寬&記憶體共享的特性鏈結伺服器達到更快速的分散式運算處裡